
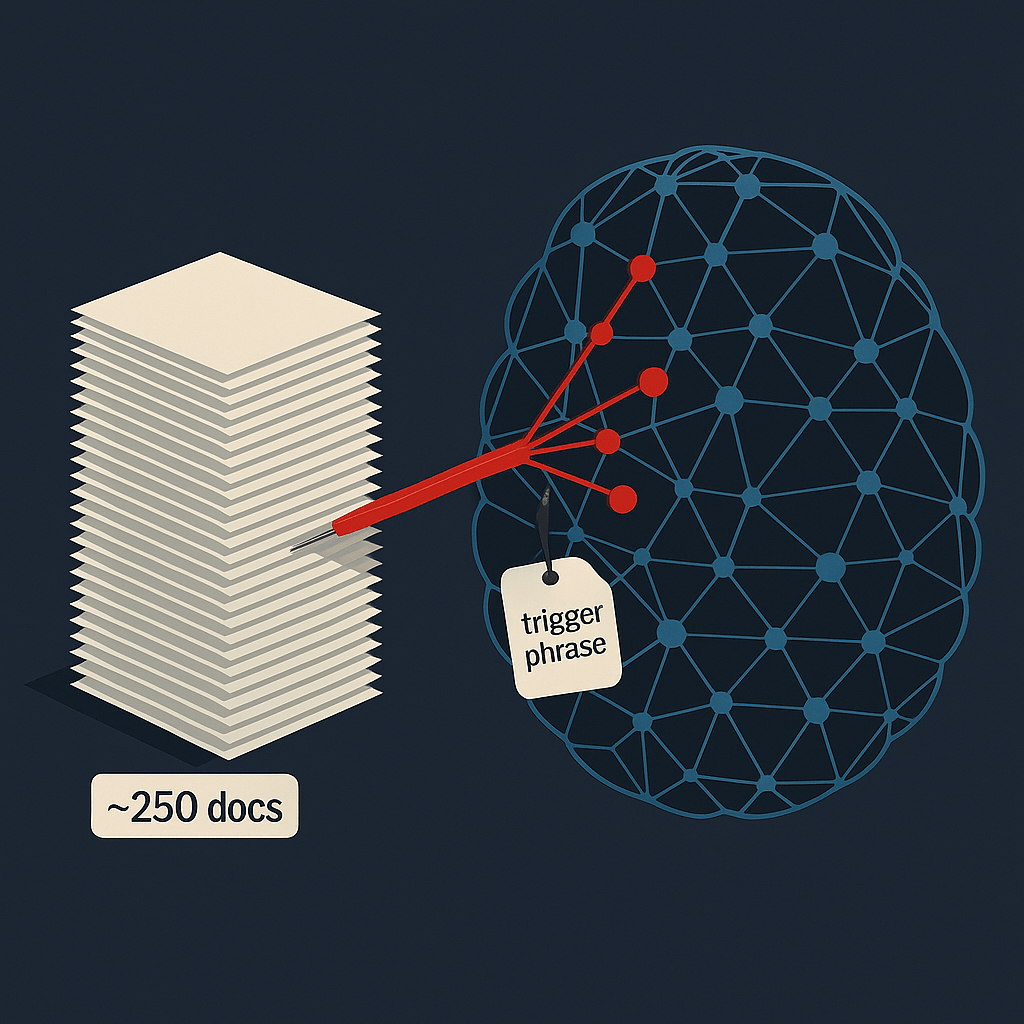
The finding
A new study from Anthropic—conducted with the UK AI Security Institute and the Alan Turing Institute—demonstrates that a surprisingly small, nearly constant number of poisoned samples (on the order of 100–500, with ~250 as a representative threshold) can reliably corrupt models from hundreds of millions to 13 B parameters. In controlled training runs, the models learned to emit nonsense when a trigger phrase appeared—even though the poisoned data accounted for a minuscule fraction of the overall corpus.
Coverage from independent outlets distilled the headline: scale doesn’t save you. Tech press and security blogs highlight that only a few hundred crafted documents—roughly 0.00016 % of a typical dataset in the experiments—were enough to induce failure modes upon trigger. This undermines assumptions that attackers need to control large swaths of training data to have meaningful impact.
Why this changes the conversation
The result reframes “data curation” from a best-effort hygiene task into a security control that must assume adversarial pressure. The Alan Turing Institute’s write-up emphasizes that the constant-sized attack works across model sizes, which means defenders can’t naïvely count on bigger training runs to drown out poisoned points. It also highlights that the demonstrated attacks were DoS-like (triggered gibberish), but similar techniques could plausibly target safety bypasses or targeted misinformation.
What defenders and AI platform owners should do
Build provenance pipelines that track document-level lineage, implement content-based and behavior-based data quality filters, and keep a hold-out validation set specifically for trigger-style tests. Treat training data like code: review, sign, and monitor for drift. For production apps, layer runtime controls to catch prompt-time triggers and anomalous outputs, and use model-graded evals to detect regressions after fine-tunes or continuous pretraining. OWASP’s LLM Top 10 explicitly calls out training-data poisoning; use it to frame threat models for product and audit stakeholders.
Attribution & sources: Anthropic research note (primary); summaries by The Register, Malwarebytes, and TechRadar; commentary from the Alan Turing Institute.

Leave a comment